
In today's fast-paced world of machine learning and artificial intelligence, reproducibility is a pillar of trust and collaboration within the scientific community.
As we delve into the intricate realm of making machine learning experiments reproducible, allow me to guide you through essential practices and priorities that will ensure your research's reliability and avoid the catastrophe of redacted papers due to methodological errors.
In this blog post, we'll explore reproducibility in machine learning.
We'll dive into the top priorities that should guide your efforts to ensure that your experiments can be recreated, verified, and built upon by others in the scientific community. From version control to documentation, each aspect plays a vital role in shaping the future of machine learning in research.
So, whether you're a seasoned ML practitioner or just beginning your journey, join me as we embark on a quest to make our experiments transparent, reliable, and accessible to all.
Together, we'll embrace the values of curiosity, community, and inclusivity as we unravel the secrets of prioritising reproducibility in the fascinating world of machine learning.
Priorities in Reproducibility for Machine Learning in Science
Reproducibility is the ability to recreate the exact same experimental results using the same code and data.
It is crucial in machine learning research and applications as it allows others to validate and build upon the work, fostering collaboration and trust in the field.
To achieve reproducibility in a machine learning experiment, I focus on the following key aspects:
Version Control

Using a version control system like Git is essential to keep track of changes in the code, data, and configurations.
By committing the code and data to a repository, we can quickly revisit past states of the project, ensuring that others can reproduce the exact experiment we conducted.
Additionally, it's good to go granular and use an experiment tracker like MLFlow or Weights & Biases, where you can save configs for each run and even register your models.
Code Organization
I ensure that the codebase is well-structured and modular.
The more you can decouple different parts of the code, the better. However, it's essential to realise that most machine learning projects are fairly intertwined in their internal structure, so there's only so much you can do.
For example, the data loader and the data it provides critically inform the input layers of the model architecture in many cases.
Organising the code means breaking down the code into functions and modules that are easy to understand and reuse.
Properly organised code reduces confusion and makes it simpler for others to navigate and replicate the experiment and build on it.
Data Management
Managing data is critical for reproducibility.
You can start by keeping a separate directory for data, as it's usually impossible to check it into the git repo.
Then, we can go on by clearly documenting the sources and preprocessing steps.
If the data is not publicly available, I like to ensure that there is a transparent process for obtaining it or providing a suitable alternative for replication.
This could even be clearing a tiny sample dataset for replication.
Configurations and Hyperparameters
I use a configuration system like Hydra (as mentioned in a previous newsletter issue and blog post) to keep track of hyperparameters and experiment settings.
This allows easy experimentation with different configurations and ensures that others can reproduce the experiment with specific settings.
It also enables fast iteration while keeping artefacts orderly.
Subscribe to receive insights from Late to the Party on machine learning, data science, and Python every Friday.
Seed Control
Randomness is essential in machine learning.
Examples could be random weight initialisation or data shuffling.
I set seeds for the random processes to ensure the reproducibility of the experiment. Actually, that is something you can also incorporate into your config files.
This way, anyone running the experiment with the same seed will get the same or at least similar results.
Documentation
Maintain clear and comprehensive documentation of the experiment.
This includes explaining the purpose of the experiment, detailing the methodology, and providing explanations for significant decisions made during the process.
While this can be achieved in a paper, it is usually best to have some less formal documentation to go with the code that can lay out the intricacies of the training and inference.
Proper documentation aids others in understanding the experiment and reproducing it accurately.
By focusing on all of these aspects, I prioritise making the machine learning experiment reproducible, contributing to the advancement and trustworthiness of the field.
Of course, we have my overview on ml.recipes with reusable code and lots of explanations about model sharing. You'll want to implement functions that fix the randomness in your model, for example (seed control). And make it easy to import and run your models.
Tools and Resources for Reproducibility
Reproducibility in machine learning isn't solely dependent on best practices.
It also relies on leveraging the right tools and resources to streamline the process.
In this section, we'll introduce you to some invaluable tools and resources that have been tried and tested by MLOps and ML engineering experts, including insights from my friends in the field.
Hydra for Configuration Management
One of the most critical aspects of reproducibility is managing configurations effectively.
Hydra is a configuration management framework that has garnered attention and praise in the machine learning community. Hydra simplifies the management of complex configurations, making it easier to experiment with different settings while maintaining clear records of each configuration variation.
Hydra's modular design and YAML-based configuration files allow you to keep track of hyperparameters, experiment settings, and code configurations effortlessly.
This tool empowers both beginners and seasoned practitioners to explore different experiment setups, ensuring that others can replicate your work precisely.
ml.recipes: Your Reproducibility Companion
On our journey to prioritise reproducibility, you'll find ml.recipes to be an invaluable resource. Developed by yours truly, ml.recipes is a curated collection of "easy wins" that can significantly enhance the reproducibility of your machine learning research.
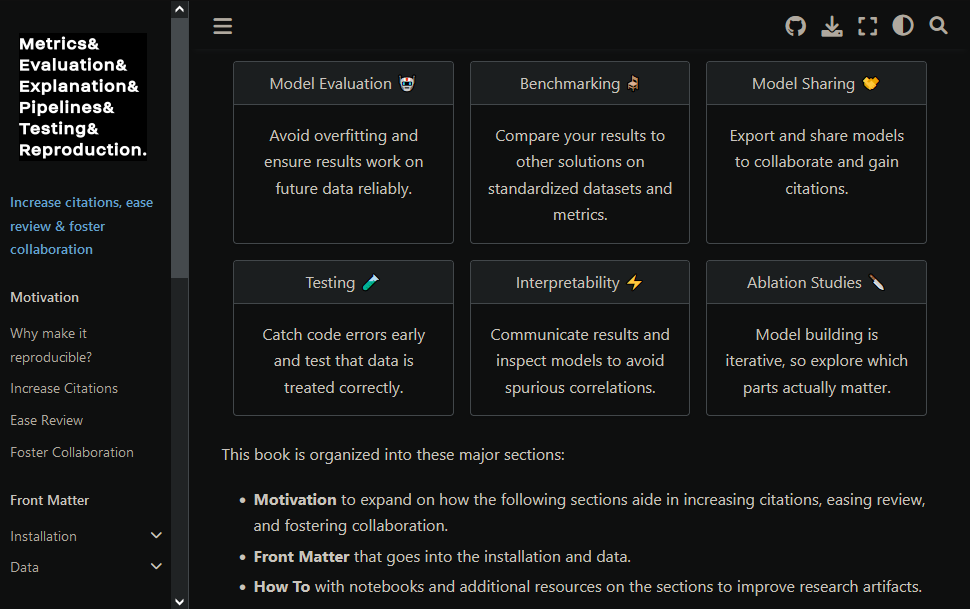
This website is designed with researchers and practicioners in mind, providing straightforward guidance and practical examples to get you started.
Whether you're working on a linear regression model using scikit-learn or tackling more complex tasks with custom convolutional neural networks, ml.recipes offers guidance and resources to make your research more robust and reproducible.
The website is organised into sections, covering essential topics like model evaluation, benchmarking, model sharing, testing, interpretability, and ablation studies. Each section offers insights, best practices, and resources to help you avoid common pitfalls and contribute to a culture of reproducibility.
Also, it's free and has practicable code examples for every step.
Weights & Biases for Experiment Tracking
Experiment tracking is a fundamental aspect of reproducibility.
Tools like Weights & Biases (W&B) are powerful for this purpose.
Experiment loggers allow you to log and track your experiments comprehensively. It captures metrics, hyperparameters, and visualisations, providing a detailed record of each experiment's conditions and results.
These tools enable you to easily compare different experiments, share them with collaborators, and ensure that every aspect of your machine learning project is well-documented.
Its intuitive interface and integration with popular machine learning frameworks make it accessible to both beginners and experienced practitioners.
PyTorch Lightning for Streamlined Training Loops
Avoiding common mistakes in hand-written PyTorch training loops is essential to ensure that scientific ML discoveries are valid.
PyTorch Lightning offers a high-level interface for PyTorch that simplifies training loop development while enforcing best practices.
By adopting PyTorch Lightning, you can abstract away boilerplate code, standardise training patterns, and reduce the risk of errors in your experiments. This ensures that your models are trained consistently, contributing to the reproducibility of your research.
Don't get me wrong. I know Pytorch ✨feels✨ great because we get to feel very smart by resetting the gradients and evaluating by hand. But unless we are pretty advanced, it's easy to make mistakes that should be avoided by simply using the right tools.
Simplifying Reproducibility for Beginners
Hydra, ml.recipes, Weights & Biases, and PyTorch Lightning are designed to simplify reproducibility, particularly for those just starting their machine learning journey.
These tools provide a solid foundation for managing configurations, organising code, and adopting best practices without the steep learning curve.
By incorporating these resources into your workflow, you'll not only prioritise reproducibility but also accelerate your research and collaboration efforts. Remember, we're all in this together, and these tools are here to support you on your quest for reproducible machine learning experiments.
In the next section, we'll delve deeper into a real-world application from the Earth sciences, showcasing how these tools and resources, including PyTorch Lightning, can be applied to ensure the reliability of your research findings.
Real-World Application in Earth Sciences
In this section, we'll look at compelling case studies that showcase how adhering to the priorities discussed earlier can significantly enhance the reliability of research results in this dynamic field.
In the realm of Earth sciences, accurate weather forecasting is paramount, and in the last year, a few promising models were published.
Nvidia's FourCastNet and Deepmind's GraphCast provide excellent examples of how reproducibility principles can be applied to enhance the reliability of weather prediction models.
- Version Control: Both of these models are available on GitHub and employ robust version control to manage changes in the model architectures and data preprocessing pipelines. This ensures that updates or modifications are well-documented, allowing meteorologists to revisit past model states and track improvements internally.
- Code Organisation: The model's codebase is organised into modular components, making it easy for meteorologists to understand and adapt the model for different forecasting scenarios. This organised structure also simplifies collaboration among interdisciplinary teams.
- Data Management: Weather data is sensitive and subject to change, making data management a critical aspect of reproducibility. While many modern-day models were trained on ERA5 reanalysis data, it would be possible to train these models on more and different data. Additionally, choices have to be made about which variables and levels to include.
- Configs with Configs: FourCastNet is a great example that utilises configuration files to keep track of hyperparameters and experiment settings, allowing meteorologists to experiment with different configurations easily. This enhances the model's versatility while ensuring that specific setups can be reproduced precisely.
- Seed Control: Randomness plays a role in weather forecasting, such as initialising model weights or data sampling. We must carefully set seeds for random processes, ensuring that different meteorologists or researchers using the model can obtain the same forecast results with the same inputs.
- Documentation: To facilitate understanding and collaboration, FourCastNet and GraphCast have some documentation, such as their Readme files, that give additional information to the formal papers. This comprehensive documentation ensures that both meteorologists and machine learning experts can work cohesively.
Impact on Interdisciplinary Collaborations
Reproducibility isn't just about ensuring the reliability of research results.
It also fosters interdisciplinary collaborations within Earth sciences. Adhering to reproducibility principles makes data-driven weather forecasting models accessible and understandable to a broader audience.
Meteorologists, climatologists, and machine learning experts can collaborate more effectively when they share a common understanding of model configurations, data sources, and code structure.
This collaboration leads to improved weather prediction models, benefiting society as a whole.
Building a Reproducible Research Culture
There is a reason why we are fostering a culture of reproducibility within the research community.
Let's delve into the significance of open-source libraries and data availability to make the most significant impact in science possible.

The Role of Open-Source Libraries and Data Availability
Open-source libraries and data availability serve as the backbone of a reproducible research culture.
They provide the tools and resources needed for researchers to build upon each other's work.
In the world of machine learning and AI, open-source libraries like PyTorch, TensorFlow, and scikit-learn have revolutionised research by enabling the sharing of code, models, and datasets. This not only accelerates scientific progress but also ensures transparency and accessibility.
Moreover, open-source libraries and datasets are invaluable for those who are just starting their research journey.
As a PhD student, I've found that access to well-documented code and openly available datasets has significantly reduced the learning curve.
It allowed me to explore and experiment with existing work, gain insights, and build upon established foundations.
From an industry perspective, open-source resources enhance collaboration and innovation.
They enable the possibility to stay at the forefront of research by leveraging the collective knowledge of the community.
Then, we can readily adopt state-of-the-art models and techniques, saving valuable time and resources in development.
The Role of Fostering an Open-Source Culture
The open-source culture does not only provide solutions but also fosters a sense of community and collaboration.
I want to emphasise the need for clear documentation and user-friendly interfaces in open-source projects.
As a PhD student, I truly appreciated projects that prioritise these aspects, making it easier for newcomers like me to contribute and learn.
Collaborative and open-source efforts often lead to faster innovation cycles and more robust solutions.
Researchers from academia, industry, and third sectors can then participate in and contribute to such initiatives, benefiting both their team and the wider research community.
Encouraging Researchers to Contribute
To truly build a reproducible research culture, we must encourage researchers at all levels to actively participate in open-source projects, share their findings, and adopt transparent practices.
This fosters a culture of trust and collaboration, making science more accessible and impactful.
I would like to emphasise that even as a student, we can find opportunities to contribute to open-source projects.
It's not just about the seasoned experts. Diverse voices and contributions matter.
By sharing your code, data, documentation, or testing, you not only help others but also enrich your own learning journey.
In industry labs, we see the value in supporting and recognising researchers actively engaging in open-source efforts.
It's a win-win situation.
Researchers gain exposure and collaboration opportunities, while the broader scientific community benefits from their contributions.
Fostering a culture of reproducibility through open-source collaboration, data availability, and knowledge sharing is vital for the advancement of science.
Let's embrace these principles and encourage researchers from all backgrounds to join us in this journey toward a more inclusive and transparent research community.
Together, we can make reproducibility a cornerstone of our scientific endeavours.
Conclusion
As we come to the end of this blog post, let's recap the essential takeaways and reiterate the profound importance of reproducibility in the machine learning community.
We ha ve explored the critical priorities for making machine learning experiments reproducible.
From version control to documentation and the adoption of valuable tools like Hydra, ml.recipes, Weights & Biases, and PyTorch Lightning, we've seen how these practices can enhance the reliability and transparency of our research.
We've ventured into a real-world application within Earth sciences, showcasing how reproducibility principles benefit interdisciplinary collaborations and contribute to accurate weather forecasting.
We've also discussed the role of open-source libraries, data availability, and fostering a culture of reproducibility.
The Importance of Reproducibility
Reproducibility is the cornerstone of trustworthy, collaborative, and inclusive research.
It allows us to validate and build upon each other's work, fostering a sense of community and innovation.
By prioritising reproducibility, we not only advance the field of machine learning but also make it accessible to researchers from diverse backgrounds.
Explore ml.recipes and Join the Journey
I invite you to explore ml.recipes, a resource dedicated to providing "easy wins" for enhancing reproducibility in machine learning research.
It's a place where beginners and experts alike can find guidance and practical examples to improve the quality and transparency of their work.
Closing Thoughts
Let's prioritise reproducibility in our research, make our experiments transparent, and contribute to a culture of trust and collaboration.
Share these insights and ml.recipes with your colleagues, especially those less experienced.
By doing so, we can advance our own work and ensure that the benefits of machine learning are accessible to all.
Together, we can shape a bright future for the machine learning community and beyond. Thank you for joining me on this journey.