
As a classically trained physicist, my natural style of programming is functional.
But in production-level code, we usually want a mix of classes and functions.
However, this can get awkward.
Oftentimes, we'll calculate some properties for a class and set them as attributes. Maybe it's the mean and standard deviation for our data class in machine learning, for example.
But that'd mean we have to initialise our class, load the data at initialisation and calculate those statistics.
That can be a bit silly in many cases.
Especially when we're building a larger class with some extra utility, this can quickly devolve into creating a monster at __init__.
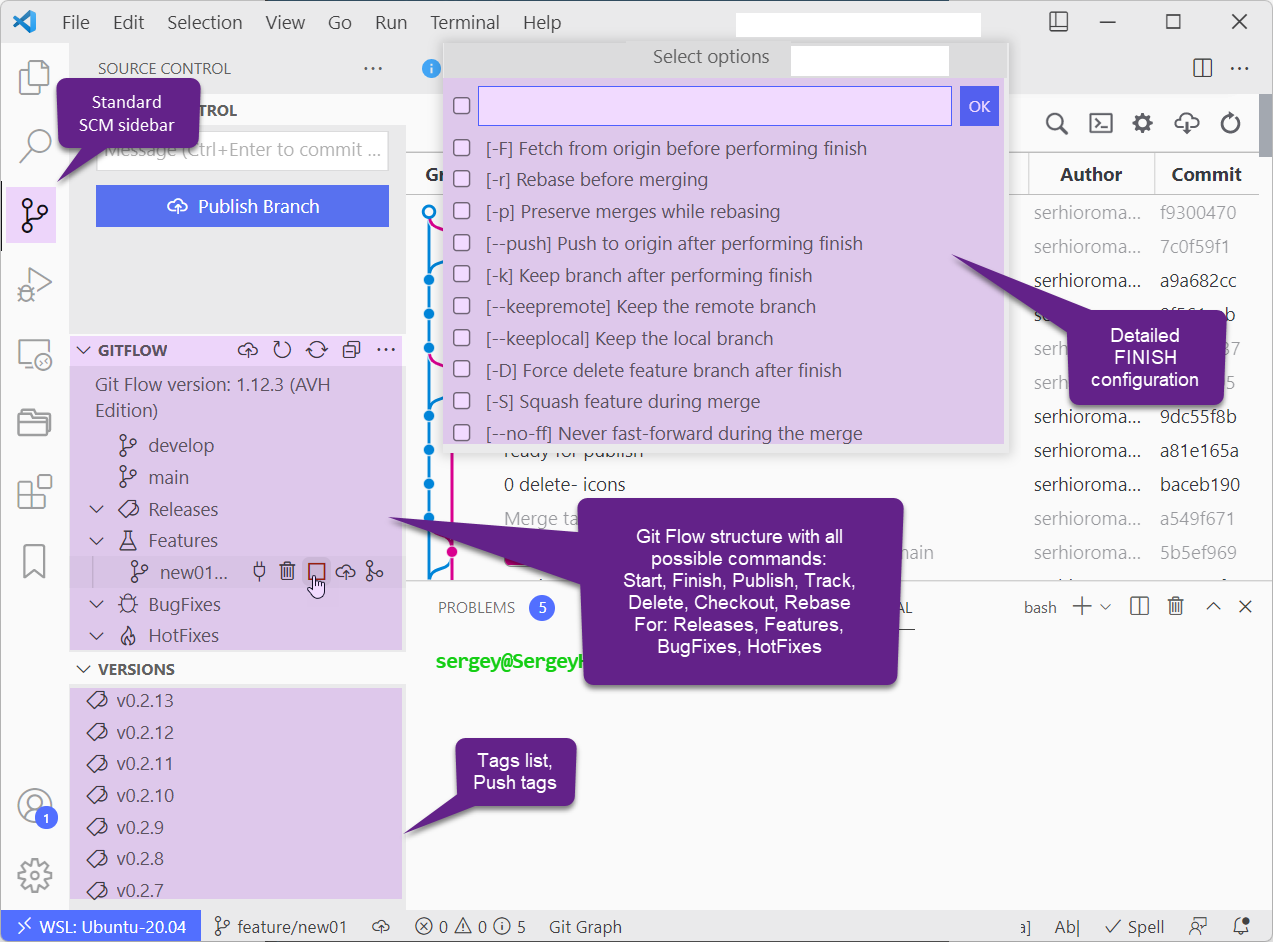
Today I learned about git flow.
It's a little utility that sits on top of git and makes my development flow much easier.
It will also make you forget git pull --rebase and git merge --squash branch immediately, because you won't need it again... maybe...
Oh and it has a VS Code extension!
I got a new toy for my computer.
It's an audio interface that has shiny knobs and buttons.

But I was disappointed right away. If you go into Spotify, there is no way to select an output device. So how do I route my Spotify music and other audio separately?!
I searched for tools and nifty open source thingamajigs. But nothing was doing quite what I wanted.
Until...
Search-engine optimization is a mystery to me.
But if you build an awesome thing and make a Jupyter book, you may as well help people find it, right?!
I was working on ml.recipes, pythondeadlin.es, and data-science-gui.de, and they have a ton of different pages with content. Things I want people to see.
My day has been a bit of a rollercoaster.
I was scrolling Mastodon, when suddenly a post appeared that made it clear I need to switch browsers.
I had been using Brave Browser for a while, I wanted to be more security and privacy-conscious, so I switched away from pure Google Chrome. That felt good... Until it didn't.
Turns out the CEO of Brave Brendan Eich donated to the campaign in California to make same-sex marriage illegal. But that was just the last straw for me, a big straw that had me act immediately. Regardless, there was some weirdness in Brave of pushing their cryptocurrency BAT on users and adding their in-browser crypto-wallet prominently without prior question. The weird "give artists crypto but they will only get it when they sign up and we won't tell them". The whole thing about Chrome not exactly being fast.
Should I give Firefox another try?
I had tried Firefox again a few years back. And I hated the experience.
Nothing was where it's supposed to be. Nothing worked how I expected. It added so much unwanted friction and there was no benefit to using it.
But it was time to give it another shot.
I was trying to solve Day 16 of the Advent of Code, when I realised that sorting values can speed up your code.
But that was the wrong choice of data structure for this problem.
Normally, I would use the set() data structure, but I was caching the inputs and needed an immutable data structure.
I knew frozenset() was a thing, but when .add() didn't work, I decided to work with tuples instead.
But the values were supposed to be unique, and the sort order didn't matter.
I was working on the Advent of Code puzzle 2022 day 16.
It's one of those "which one is the highest value path" problems, where recursion comes into play.
It's one of those "this problem is huge and you want to cache your function" problems.
Usually, one would use lru_cach(maxsize=None) for this one from the functools library, or if you're on a newer version of Python, you could use the alias for that call which is just cache().
This cache works fairly simple:
Most websites use Gzip to compress the data to send it to you.
The idea is that internet speeds are still much slower than compute time, so spending compute to decompress a file that was sent to you, reduces load-times overall, compared to an uncompressed site.
So naturally I enabled it on this website.
This website is generated with a static website generator called Nikola.
It's written in Python, so it's easy for me to add changes, compared to Hugo, Jekyll, or Atom.
Why static sites?
I use Notion to plan a lot of high- and low-level goals in my life.
One example is that I sit down every Saturday morning to review my last week and plan the next.
I try to journal and sometimes I even accomplish a nice streak of journaling, which is always great for my mental health.
It's Advent of Code! 🎄
Every year I add to my utils.py and try to make the coding experience a bit nicer.
This year, I discovered that once again I didn't update the Readme after the last year. I also didn't finish last year, must've been a stressful time...
On this website and places like the profile Readme on Github, I figured out that you can use HTML comments to insert text at certain locations, basically like a placeholder.
So I could do this for the Advent of Code readme, to have a place for the stars to go once my pytest test cases pass, right?
I was reading through the Mastodon API documentation to figure out how to get my posts.
On this website, I have a small widget that shows my last "Tweets" but unfortunately I locked myself out of my Twitter account after accidentally setting my age to under 13, while deleting personal information. This means my Twitter timeline isn't available, so I made the jump and figured out how to use the Mastodon API to pull a user's timeline.
For Twitter this is an entire thing:
Gotta love a bit of self-referential writing.
I read about TIL (Today I Learned) posts by Simon Willison, as an easy way to document small snippets of learning and get in the habit of writing and publishing.
Then I saw multiple people do this inspired by J Branchaud: