
Model Evaluation¶
Applying machine learning in an applied science context is often method work. We build a prototype model and expect want to show that this method can be applied to our specific problem. This means that we have to guarantee that the insights we glean from this application generalize to new data from the same problem set.
This is why we usually import train_test_split() from scikit-learn to get a validation set and a test set. But in my experience, in real-world applications, this isn’t always enough. In science, we usually deal with data that has some kind of correlation in some kind of dimension. Sometimes we have geospatial data and have to account for Tobler’s Law, i.e. things that are closer to each other matter more to each other than those data points at a larger distance. Sometimes we have temporal correlations, dealing with time series, where data points closer in time may influence each other.
Not taking care of proper validation, will often lead to additional review cycles in a paper submission. It might lead to a rejection of the manuscript which is bad enough. In the worst case scenario, our research might report incorrect conclusions and have to be retracted. No one wants rejections or even retractions.
So we’ll go into some methods to properly evaluate machine learning models even when our data is not “independent and identically distributed”.
import pandas as pd
penguins = pd.read_csv('../data/penguins_clean.csv')
penguins.head()
Data Splitting
The simplest method of splitting data into a training and test data set is train_test_split(), which randomly selects samples from our dataframe.
This method essentially makes a very big assumption. That assumption being that our data is "independent and identically distributed" or i.i.d..
That simply means that each measurement for a penguin does not depend on another measurement. Luckily for penguins that is mostly true. For other data? Not so much. And it means that we expect that we have a similar distribution of measurements of our penguins to the unseen data or future measurements.
from sklearn.model_selection import train_test_split
num_features = ["Culmen Length (mm)", "Culmen Depth (mm)", "Flipper Length (mm)"]
cat_features = ["Sex"]
features = num_features + cat_features
target = ["Species"]
X_train, X_test, y_train, y_test = train_test_split(penguins[features], penguins[target], train_size=.7, random_state=42)
X_train
Stratification
Usually, our target class or another feature we use isn't distributed equally.
penguins.groupby("Species").Sex.count().plot(kind="bar")

In this case it's not very extreme. We have around twice as many Adelie than Chinstrap penguins.
However, this can mean that we accidentally have almost no Chinstrap penguins in our training data, as it randomly overselects Adelie penguins.
y_train.reset_index().groupby(["Species"]).count()
We can address this by applying stratification. That is simply sampling randomly within a class (or strata) rather than randomly sampling from the entire dataframe.
X_train, X_test, y_train, y_test = train_test_split(penguins[features], penguins[target[0]], train_size=.7, random_state=42, stratify=penguins[target[0]])
y_train.reset_index().groupby("Species").count().plot(kind="bar")

Let's quickly train a model to evaluate
from sklearn.svm import SVC
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler, OneHotEncoder
num_transformer = StandardScaler()
cat_transformer = OneHotEncoder(handle_unknown='ignore')
preprocessor = ColumnTransformer(transformers=[
('num', num_transformer, num_features),
('cat', cat_transformer, cat_features)
])
model = Pipeline(steps=[
('preprocessor', preprocessor),
('classifier', SVC()),
])
This difference is not drastic, as we can see in the plot above. That changes however, when we have minority classes with much less data than the majority class.
Either way it's worth it to keep in mind that stratification exists. The stratify= keyword takes any type of vector as long as it matches the dimension of the dataframe.
Cross-Validation
Cross-validation is often considered the gold standard in statistical applications and machine learning.
Cross-validation splits the data into folds, of which one is held out as the validation set and the rest is used to train. Subsequently, models are trained on the other folds in a round-robin style. That way we have models that are trained and evaluated on every sample of the dataset.  Scikit-learn cross-validation schema. [Source]
Scikit-learn cross-validation schema. [Source]
Cross-validation is particularly useful when we don't have a lot of data or the data is highly heterogeneous.
from sklearn.model_selection import cross_val_score
scores = cross_val_score(model, X_train, y_train, cv=5)
scores
print(f"{scores.mean():0.2f} accuracy with a standard deviation of {scores.std():0.2f}")
Now we know there are some folds this support-vector machine will do exceptional on and others it does quite well on only getting a few samples wrong.
Time-series Validation
But validation can get tricky if time gets involved.
Imagine we measured the growth of baby penguin Hank over time and wanted to us machine learning to project the development of Hank. Then our data suddenly isn't i.i.d. anymore, since it is dependent in the time dimension.
Were we to split our data randomly for our training and test set, we would test on data points that lie in between training points, where even a simple linear interpolation can do a fairly decent job.
Therefor, we need to split our measurements along the time axis 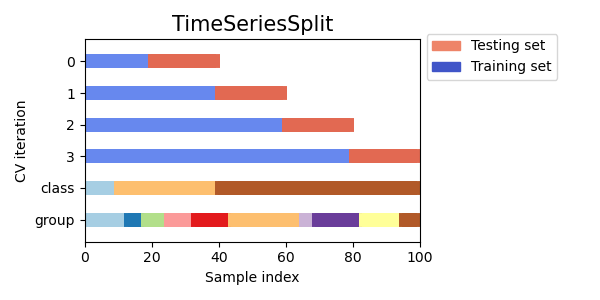 Scikit-learn Time Series CV [Source].
Scikit-learn Time Series CV [Source].
import numpy as np
from sklearn.model_selection import TimeSeriesSplit
X = np.array([[1, 2], [3, 4], [1, 2], [3, 4], [1, 2], [3, 4]])
y = np.array([1, 2, 3, 4, 5, 6])
tscv = TimeSeriesSplit(n_splits=3)
print(tscv)
for train, test in tscv.split(X):
print("%s %s" % (train, test))
Spatial Validation
Spatial data, like maps and satellite data has a similar problem.
Here the data is correlated in the spatial dimension. However, we can mitigate the effect by supplying a group. In this simple example I used continents, but it's possible to group by bins on a lat-lon grid as well.
Here especially, a cross-validation scheme is very important, as it is used to validate against every area on your map at least once.
from sklearn.model_selection import GroupKFold
X = [0.1, 0.2, 2.2, 2.4, 2.3, 4.55, 5.8, 0.001]
y = [1, 2, 4, 2, 2, 3, 4, 5]
groups = ["Europe", "Africa", "Africa", "Africa", "America", "Asia", "Asia", "Europe"]
cv = GroupKFold(n_splits=4)
for train, test in cv.split(X, y, groups=groups):
print("%s %s" % (train, test))
Conclusion
A simple random split of the data works on toy problems, but real-world data is rarely i.i.d.
We looked at different ways that we can evaluate models that violate the i.i.d. assumption and how we can still evaluate their performance on unseen data without obtaining artificially high scores.