
I'm obsessed with Alphacode.
How do you go from a mediocre text generator to an AI that can compete competitively?
Deepmind attempts this with AlphaCode.
Let's look at their research together.
I can safely say the results of AlphaCode exceeded my expectations. I was sceptical because even in simple competitive problems it is often required not only to implement the algorithm, but also (and this is the most difficult part) to invent it. AlphaCode managed to perform at the level of a promising new competitor. I can't wait to see what lies ahead! ~ Mike Mirzayanov

😼 The Problem
Competitive programming is a whiteboard interview on steroids.
You get:
- Text problem statements
- Description of inputs
- Specifics of outputs
You have to understand and implement a solution.
Finally there are hidden tests.
The Backspace Problem (Mirzayanov, 2020):

💾 The Data
Best results were obtained by Pre-training on the entirety of Github. Not just Python (the target language) but C++, C#, Go, Java, Rust......
Then fine-tuning the AI on the CodeContests dataset
- Teach AI code
- Get into competitions
- ???
- Profit!
3️⃣ ???
There is a third step:
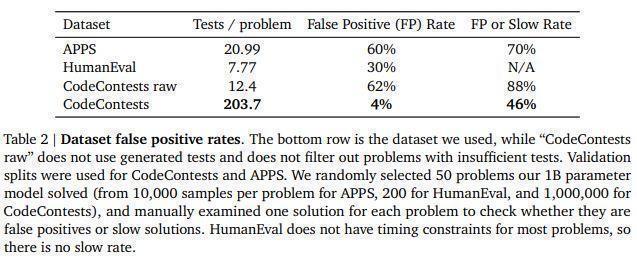
Reduce False Positives.
Create extra hidden tests.
Large test variance reduces false positives.
Implementing "slow positives" reduces inefficient code.
Going from 12 to 200+ tests/problem shows significant improvement!
☝️ Intermission: Amazing tools
"Hypothesis" can automatically generate more tests for you:
Advent of code is competitive coding light often with "slow positives":
🔬 The Evaluation
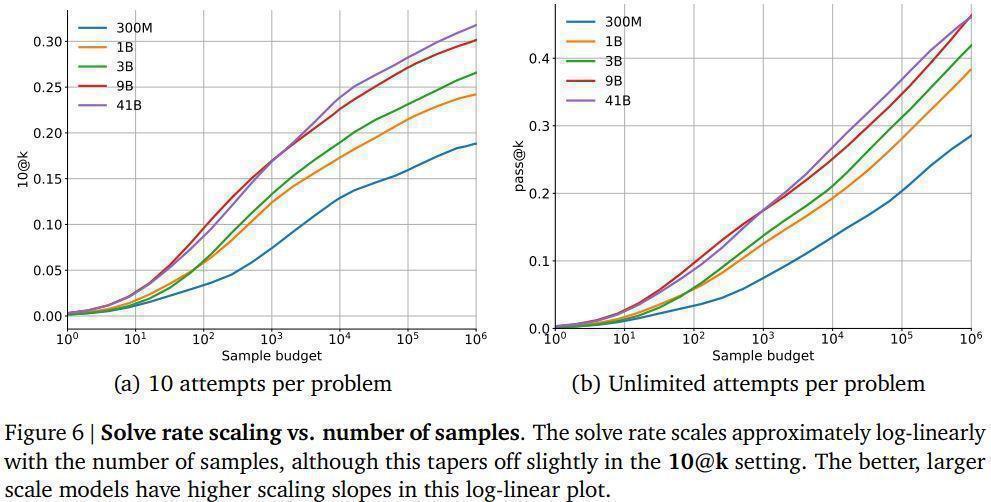
You can't just submit solutions until one works in competitive coding.
So to simulate that Deepmind settled on a n@k metric.
Submit n solutions to k coding problems.
They're going for n=10, so 10@k to evaluate AlphaCode.
(Also pass@k as an upper bound.)
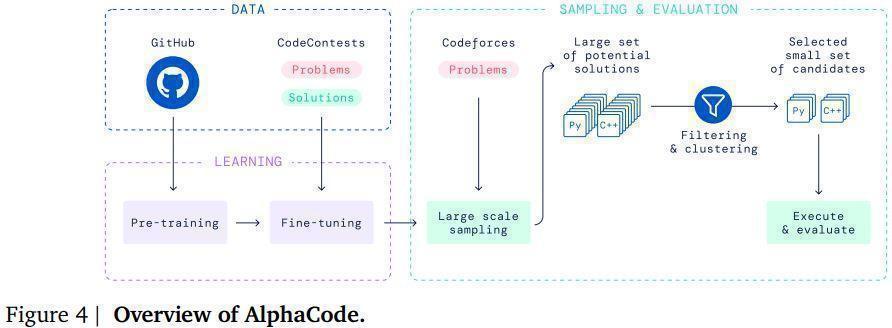
🧮 The Algorithm
- Train a model on a bunch of code.
- Then focus on contests.
- Then generate a bunch of potential solutions.
- Filter out trivial solutions.
- Cluster similar solutions.
- Select candidates (at most 10).
- Submit and evaluate.
🤖 It's a transformer!
Specifically, encoder-decoder architecture takes flat text + tokenized metadata.
Tokenizer: SentencePiece (Kudo & Richardson, 2018)
Internally, uses multi-query attention (Shazeer, 2019) but shared key & value per attention block.
Visualize the multi-query model here
🦾 Let's stop here. This is long.
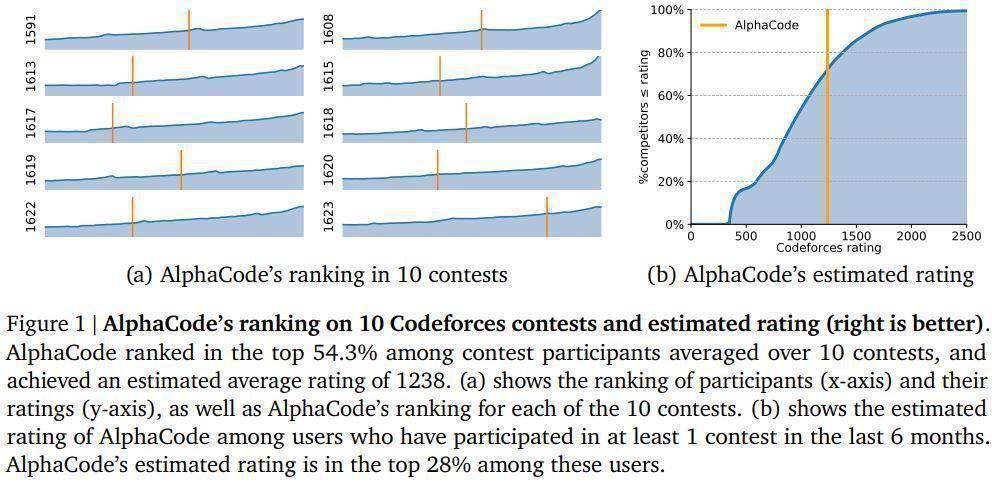
AlphaCode is an above-average competitive programmer.
The paper has ablation studies on tricks in the transformer
and compares impact of different pre-training datasets
and different training tricks.
It's a great read.
Conclusion
- Pre-train on huge GitHub data
- Fine-tune on CodeContest data with extra test cases
- Transformer with multi-query attention
- Generate then filter 99% & cluster solutions
- Submit a max of 10
Read the Deepmind blog post