
We have something to celebrate!
The Youtube channel was accepted into the Youtube Partner programme.
And that's why I want to share 100 machine learning tips with you in this blog post and accompanying video.
Let's get right into it.
Learn about Shortcuts and Compression
First, if you want to understand neural networks, if you learn about shortcuts and compression, you will understand 90% of architectures.
Treat missing data correctly
When you have missing data, just use mean amputation.
So replace your NaNs with the mean of the population, and then add another column that is binary, and just has a one wherever you had a missing value.
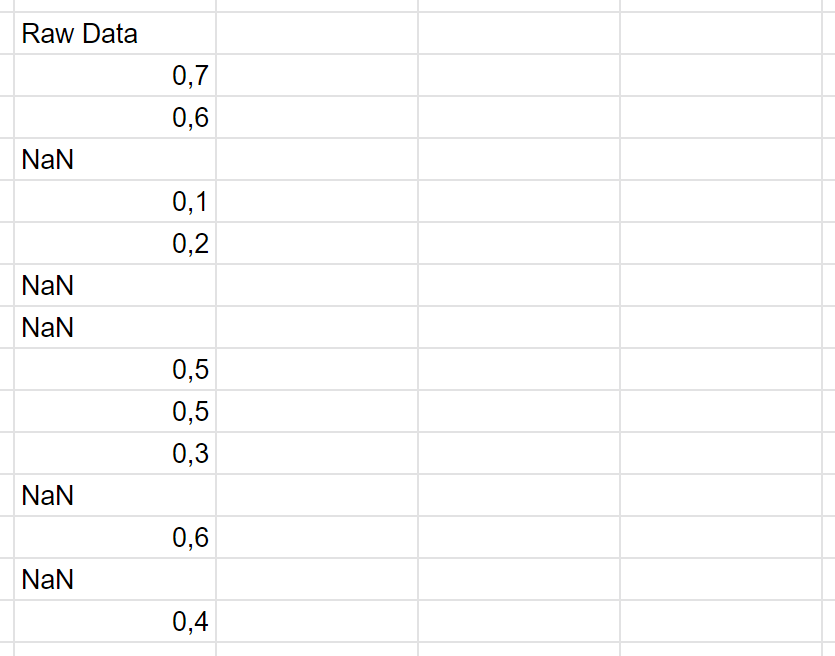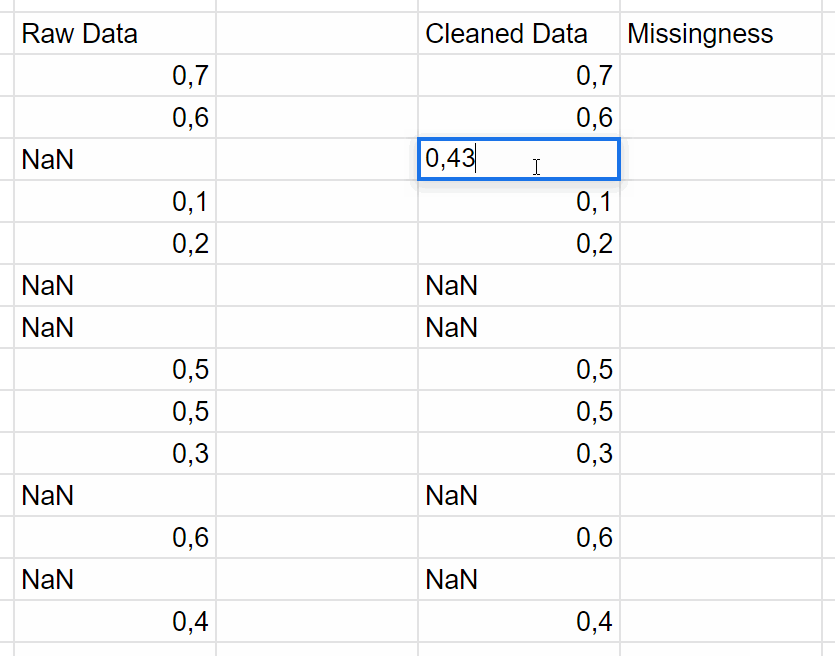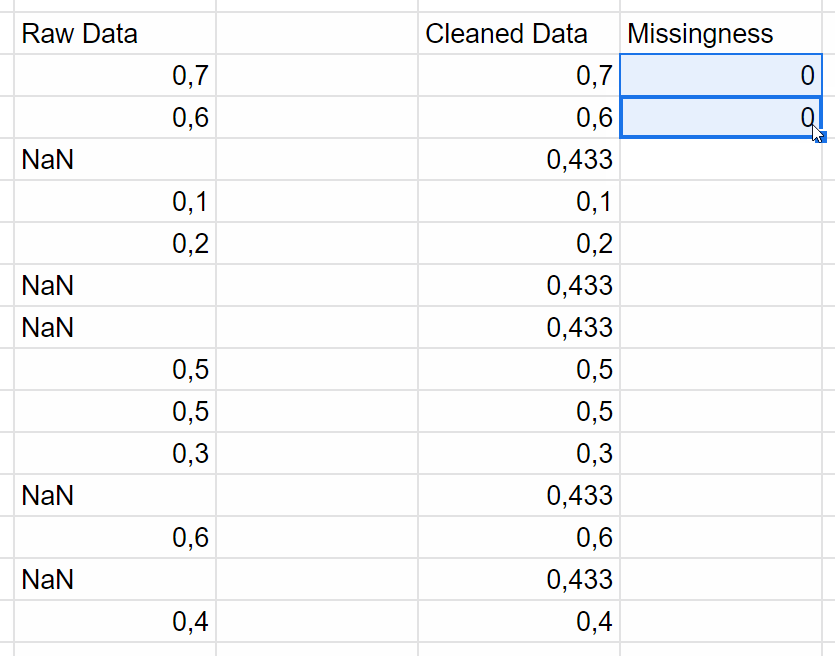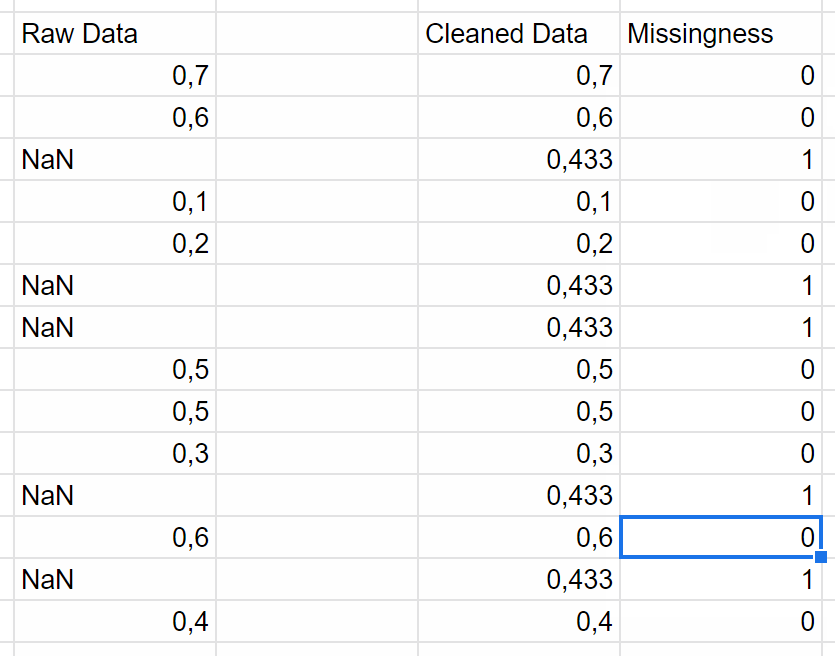
I call it missingness as a feature.
It works really well and I wrote more about this in this newsletter issue.
Read the Convnext 2020 paper for CNNs

If you work with convolutions, then read the ConvNext 2020 paper, where they have a lot of working tricks getting the accuracy of the CNNs up to transformer level.
And yeah, they're writing about fewer activations, fewer normalizations, larger kernels, and evaluate how this affects your convolutional neural network.
Let experts label your data
Get experts to label your data, because getting cheap labour to do it often gives you bad data.
And if you have good labelled data, that usually means that you can actually have fewer labels and much better model.
The relationship is non-linear, how you can improve all your training on everything you do by just having experts label your data.
Learn about Transfomers
Transformers are eating the world.
Learn how they work, and you can definitely apply them to your field.
The Illustrated Transformer is a great intro!
For regression don't forget R²
The coefficient of determinations is a great tool for regression problems.
Try it out to evaluate your model performance.
GANs are easier to train than you think
Generative adversarial networks are much cheaper and much easier to train than you think.
Especially if you're trying CycleGANs, they are a little bit trickier to train, but they need much less data and they are really great.
Get to know your data
If you want to do exploratory data analysis with your data so you can actually understand what's going on, and that will give you a huge advantage in actually building good machine learning models.
I talk about EDA in my Skillshare courses.
Split out your test set as soon as possible
Split out your test set as early as possible.
That way you can avoid a lot of ways to overfit and to cheat on your data.
Do it as early as possible, even before you do your scaling, split out your test set.
My Skillshare course on predicting time-series data has an example on why.
Transfer learning is great
Try out transfer learning.
It's using pre-trained neural networks, usually, or pre-trained machine learning models, and you just fine tune them on your data set that way you retain a lot of the complexity they have from larger training data sets.
And it's very fast to use, and very cheap for you to train and experiment, and gets fast results.
My most cited paper (as of July 2022) showed transfer learning on seismic data.
Go with the basics
You can get a lot done with Keras or PyTorch Lightning.
Don't get fooled by shiny library syndrome.
You'll barely need the basics in the beginning.
So start with those and only graduate when you're actually need it.
Tune your hyperparameters
Optimise your hyperparameters, and do it automatically.
Use something like Ray or Optuna to just get the job done.
That's how you get better models for free.
Use Cross-validation
Use cross validation whenever you can.

Make Machine Learning work in the Real World
e-Book
I wrote a small ebook about applying validation techniques to different types of real-world datasets. Going into short examples how different data types have to be treated to avoid overfitting.
I touch on the topics of:
- overfitting
- train-test splits
- cross-validation
- stratification
- spatial validation
- temporal validation
- production models
- data drift
I made it complementary with a newsletter subscription to my weekly machine learning newsletter. Subscribe to receive insights from Late to the Party on machine learning, data science, and Python every Friday.
Baseline Models
Build baseline models.
Use one from your domain like a classic model that you can implement or, well, use existing code for and then also use a basic machine learning model.
At best use a linear model like linear regression or logistic regression, or maybe a random forest, but random forests might already be your advanced model.
Really go as basic as possible.
Maybe even try a DummyClassifier.
Use Data Augmentation
Definitely use data augmentation because that's a way to basically increase the diversity of your data.
This can include changes in lighting or orientation, for example.
Then you can get more training data for free.
You could try Albumentations
Use Explainable AI
Use a library like SHAP or Alibi that can help you with explainability.
It's not so much for you, but it makes it a million times easier to communicate with stakeholders and domain scientists, and build trust.
Building trust is essential.

Be careful with benchmark results
Benchmark results can be flawed.
Keep that in mind when chasing numbers, because, well, the paper found that a lot of the models trained on ImageNet, don't even generalise to ImageNet.
So, everything with a grain of salt.
Does Imagenet generalize to imagenet?
Put your papers on Arxiv

When you publish a paper, consider putting it on Arxiv or on other pre-print service.
And that way you can, well, get early citations, feedback, and establish priority, so no one can scoop you.
And it makes open science, which is amazing.
Cut through the noise
Cut through the noise, listen to podcasts or my newsletter.
Subscribe to receive insights from Late to the Party on machine learning, data science, and Python every Friday.
Publish Your Code
Always publish your code.
If you publish your code, it's easy to reproduce what you did, and then people can build on it.
You can use GitHub, you can use Zenodo for a DOI, but in the end, if you publish your paper, definitely publish your code.
My most cited paper is I think because I made it super easy with a Jupyter notebook to replicate it.
Talk to Domain Scientists
Always speak with domain scientists.
Domain scientists have decades of experience in a field.
So if you want to get a head start, you should, well, basically get some priors from them.
What works, what doesn't work.
And then, it's easy to implement that kind of expert knowledge in neural networks, right?
Survey the Literature
In addition to talking to domain scientists, you always want to survey the literature.
There's nothing more embarrassing than publishing a deep learning architecture, a new neural network, for a solution that is analytical and solved for 50 years.
Don't do that.
Use benchmarks
Use benchmarks to test new models and architectures, that way you have an established baseline, and you can actually see how well or how poor your new fancy thing is doing.
And you can tell everyone else.
Check for Class Imbalances
Always check your data set for class imbalances.
If you have an accuracy of 95%, but you have a 19 to one split of your classes it's basically a coin flip.
Check out my mini-ebook on validation that includes class imbalances.
Build Trust through communication
Always build trust.
Machine learning adoption is about trust.
And if you communicate well, then people will think your solutions are working.
And that way, well, that way you can keep your job.
Build Benchmarks for Credibility
One way to establish your credibility in a field is to establish a well-documented and good benchmark that other people can work with.
A good way is also to, well, maybe have a notebook or some example code to go with it that people can get started and try to beat your score.
Here's a nice example.
Why class imbalance is difficult
The hard part about class imbalances is that we're usually interested in the minority class.
Like the majority class is easy to collect.
So really when we are working with class imbalances, we can often throw away a lot of the majority class data, just random sample from it.
Or look if it has correlations first.
Make Machine Learning work in the Real World
e-Book
I talk about class imbalances in my mini-ebook among the many topics like:
- overfitting
- train-test splits
- cross-validation
- stratification
- spatial validation
- temporal validation
- production models
- data drift
I made it complementary with a newsletter subscription to my weekly machine learning newsletter. Subscribe to receive insights from Late to the Party on machine learning, data science, and Python every Friday.
Use Pytorch lightning
When you use PyTorch, use PyTorch Lightning.
I've seen it way too much that people forget to zero their gradients or something like that.
Never upgrade CUDA
Never try to upgrade CUDA. Especially not on a shared resource or shared instance.
Train your models online
You can actually train most models online for free.
Use Colab, Kaggle, Paperspace, or AWS studio Lab.
Don't Overpromise Solutions
Build trust with stakeholders meeting them where they are, and you never overpromise.
Always promise what you can deliver, and then hopefully over deliver.
Overfit a small batch for debugging
Overfit a small batch of data to your model.
That way you can debug and see that your model is actually working as it's intended.
Use Adam or SGD Optimizers
In almost all applications that you want to use, Adam, as the optimizer, or SGD.
So stochastic gradient descent without any momentum is what you'll want to use.
SGD is a little bit slower, but can find smaller minima, and Adam is usually faster, and good for iterations and experimentation.
Set your gradients to None
In PyTorch, you can set your gradient to None, instead of zero, which will often speed up your code.
optimizer.zero_grad(set_to_none=True)
Try Gradient clipping if you get NaNs
Gradient clipping, which was first introduced in recurrent neural networks and avoids exploding gradients is a great way to make your training more stable, especially if you have noisy data or high variance in your data.
torch.nn.utils.clip_grad_norm_(model.parameters(), clip)
Fuse small operations
If you have small operations, and a lot of them, you can actually use just-in-time compiling, in both TensorFlow and PyTorch, to fuse small app operations into a larger kernel.
@torch.jit.script def collapse(x, dim: int): if dim > 3: dim = 3 return torch.sum(x, dim=dim)
A new LLVM-based JIT compiler is now available for CPUs that can fuse together sequences of PyTorch ops to improve performance. While we’ve had this ability for some time on GPUs, this release brings this capability to CPUs. For certain cases this can bring massive speedups!
— PyTorch (@PyTorch) October 25, 2021
6/9
Reduce the batch size to replicate papers
Are you trying to replicate a paper and your GPU is too small? Well, in that case, you can reduce the batch size to actually fit it into memory.
Don't mix BatchNorm and biases
BatchNorm normalises your statistics.
So you can actually switch off the bias in the layer right before your batch normalisation layer.
nn.Conv2d(..., bias=False, ....) nn.BatchNorm2d(...)
Pin Pytorch memory
You probably want to pin your memory in PyTorch.
torch.utils.data.DataLoader(..., pin_memory=True, ...)
Check your weight decay
Check that your weight decay for your bias and your norm layers is set to zero, because PyTorch didn't do it for the longest time, and might still not do it.
And this is very important.
The other libraries, you're probably fine, but definitely check.
optim_groups = [ { "params": list(decay), "weight_decay": train_config.weight_decay, }, { "params": list(no_decay), "weight_decay": 0.0, }, ] optimizer = torch.optim.AdamW(optim_groups, ...)
Adapted from Andrej Karpathy's minGPT.
Use gradient accumulation
When you have a smaller GPU and you are trying to train your model anyway, sometimes you have to reduce the batch size. So then you can use gradient accumulation to still get the stabilised gradients from multiple batches. It's really useful.
Careful with Softmax
We often use Softmax in our outputs so that we can get a classification. Now, the problem is that Softmax scales the largest raw output to one. And sometimes our outputs are nonsense. They're just noise, and it still finds the minimally higher one. So oftentimes it's worth it to have a look at your raw outputs, just to check if there is actually one that stands out.
Use Mixed Precision
Use mixed precision or single precision to speed up your training.
from tensorflow.keras import mixed_precision policy = mixed_precision.Policy("mixed_float16") mixed_precision.set_global_policy(policy)
Inspect bad data points
Look at data your model is performing poorly on. It's basically super powered EDA. Those are the hard problems.
Build redundancy in your MLOps
In an MLOps system, you need to be ready to switch off models that don't perform anymore.
So build in redundancy.
Pytorch async data loading
The PyTorch data loader has the num_workers keyword.
If you set that over zero, it means that it can now use the CPU to process data while you are training your network on the GPU.
It's asynchronous and often it's faster.
torch.utils.data.DataLoader(..., num_workers=4, ...)
Use the Classification Report
Scikit-Learn has the classification_report, which is a great way to get a quick overview on how your data is doing even if there's class imbalance.
And especially if there's class imbalance.
Read the documentation.
Keras Lambda Layers
You can get really far with Keras Lambda Layers without adding too much complexity in going to straight TensorFlow, for example.
from tf.keras.layers import Lambda model.add(Lambda(lambda x: x**2))
Here's the Keras LambdaLayer documentation.
Don't use Random Forests for Feature Importances only
Random forests are great, but don't use random forests just for the future importances.
You can use any model and apply the permutation importance to it to get a much better overview of how each feature is contributing to your solution.
from sklearn.inspection import permutation_importance r = permutation_importance(model, X_val, y_val, n_repeats=30, random_state=0)
Check out the permutation importance documentation.
Use XGBoost and Neural Networks
For tabular data, use XGBoost.
For anything else, be it audio, speech, anything, use neural networks.
⚡️Preprint: Why do tree-based models still outperform deep learning on tabular data?
— Gael Varoquaux @GaelVaroquaux.bsky.social (@GaelVaroquaux) July 19, 2022
We give solid evidence that, on tabular data, achieving good prediction is easier with tree methods than deep learning (even modern architectures) and explore whyhttps://t.co/qft4LgZm0z
1/9 pic.twitter.com/M1vpC5RL9e
Einsum is great!
NumPy, PyTorch, and TensorFlow have the Einsum operation, which is a way to use the Einstein summation convention to combine a bunch of different calculations on your tensors.
It's very good, it's used in all transformer libraries.
Learn how to use it.
import numpy as np mat_t = np.einsum("ij->ji", mat)
Here's the Numpy docs on einsum.
The Einstein notation is pretty useful generally.
Research Adjacent Fields
Research similar fields for applications that kind of are like yours.
That way you can basically benefit from all the insights they have already generated, and yeah, get a headstart.
Hydra for Configs
Check out the library, Hydra for configurations.
That way you can take it out of your code, which makes code changes so your git much more lean. That means it makes experimentation much more traceable and trackable.
Hydra lives here.
MissingNo Library
Try out the MissingNo library.
If you have any columns, any samples missing, this is great to explore.
MissingNo is here on Github.
Pandas Profiler
Pandas profiler is a great way to automate reporting on your dataset, and you can see a lot of statistics, visualisations, and even class imbalances in there.
Pandas Profiling is great.
I also go over Pandas Profiling in my Skillshare course
Paperswithcode
If you find a really cool paper, look on paperswithcode, because oftentimes people publish their code that they use to generate the results in their papers on GitHub, and that is a way to link them.
Papers with code? Great.
It's like- most papers have something on there, and it's just fantastic resource.
Check out Papers with code!
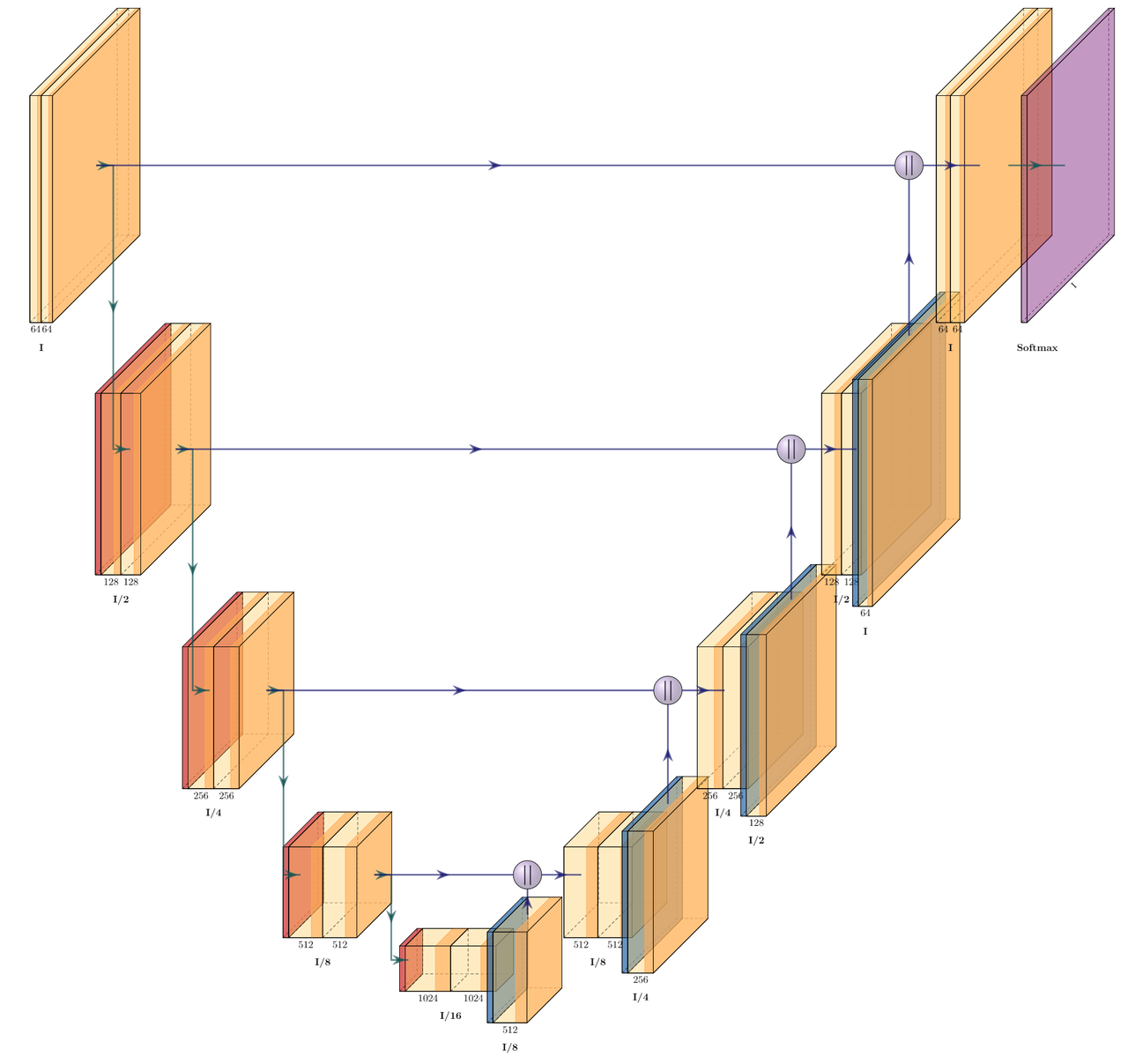
Try Unets
Unets are like magic.
Learn to use them.
They're used in almost any field that uses convolutional neural networks.
Use EarlyStopping
EarlyStopping is a fantastic way to get your model right before it would start overfitting, so use it as a callback, it's available in both PyTorch and in Keras, and very easy to use.
And yeah, you get a good model for free.
Here's the keras documenations.
Set your Dropout right
If you use Dropout, a value between 0.5 and 0.2 is probably a good idea.
Check out Profilers
TensorFlow and PyTorch both have profilers to see what is running slow in your model.
Experience Replay
In reinforcement learning, you probably want to use experience replay.
It's a great way to speed up your training and to reduce the compute.
Use Schemas in production
In production, use schemas like Great Expectations or Pandera to validate your input data, and yeah, see that you get exactly what you needed into your machine learning models.
Empty Pytorch and TF cache
If you're playing around on Colab, Kaggle, then PyTorch, Tensorflow, both have great ways to empty the cache.
If you're training a model and it's still there, sometimes you get problems.
tf.keras.backend.clear_session()
or
torch.cuda.empty_cache()
Normalize your inputs
Absolutely normalise your input data for neural networks.
Try the scikit-learn StandardScaler.
Use Robust Scalers
Data with outliers is difficult to normalise.
So use a robust scaler, it's in Scikit-learn, but you can also use the interquartile range to just get it done yourself.
Use the scikit-learn RobustScaler.
Find difficult to train samples
You can find difficult samples in your data by monitoring the variants of your gradients, because hard data will cause a higher error.
And that means you can find those difficult training samples, right? That way.
Read the paper.
Arbitrary input sizes
Make your neural network accept arbitrary input sizes.
It'll make your life so much easier later on when you actually want to put it into production, or publish it and people can use it with any data they like.
input = Input(shape=(None, None, 3))
Use GANs for real-world data
Generative adversarial networks are great for real-world data.
They can model non-normal data.
So data that isn't Gaussian distributed, essentially, and are just a great replacement for Mean Squared Error, in a way.
Check my short summary of the Deepmind Nowcasting paper
Set up Data pipelines
Setting up proper data pipelines is going to ensure that your experimentation will be so much faster.
It's a little bit more overhead, but the reward is immense.
Use Confusion Matrixes
Confusion Matrixes are great.
Use them.
Find the maximum batch size
When you set up your training, try to find the maximum batch size.
It doesn't have to be a multiple of two.
That is a myth.
"Do Batch Sizes Actually Need to be Powers of 2?" The answer is no, there is no noticeable training speed diff. Thank you. In class, I usually mention that it's
— Sebastian Raschka (@rasbt) July 1, 2022
1. mostly done for historical reasons
2. makes it look less like cherry-picking
3. constraints the number of hypeparam https://t.co/HfBFxSOTmN
Just find the largest size, and that way you can get your most out of the training.
Use checkpoints on Colab
If you work on a platform like CoLab, that has a time limit, you can usually, well, stop training right before, export your model, save it away.
And then you can start from that checkpoint and keep training.
checkpoint_filepath = "/drive/colab/checkpoints" model_checkpoint_callback = tf.keras.callbacks.ModelCheckpoint( filepath=checkpoint_filepath, save_weights_only=True, save_best_only=True ) model.fit(callbacks=[model_checkpoint_callback]) model.load_weights(checkpoint_filepath)
Checkpoint on the keras docs.
Learn the different model APIs
TensorFlow and PyTorch have sequential, functional, and an object-oriented API.
You are going to probably use most of the functional while you're experimenting, but in operations, you probably want to actually use the object-oriented one, because you can just subclass from it.
Debug with Tensorboard
Tensorboard is great for debugging, especially because you can use it to measure timings on your different operations.
Read the Tensorboard docs.
Pre-allocate memory for dynamic tensors
If you are building up tensors on the fly, then you are probably going to want to allocate the tensor before, because that saves time and memory.
Feature engineering
For feature engineering, especially on time series and physical data you can often calculate a bunch of statistics.
For example you can generate the variance, the mean, often over a window, and that way generate a bunch of really good features, and you can use feature selection to find the most important ones, the most expressive ones for your kind of model.
Here's an example on volcano data!
Random Forest can overvalue noisy features
Be aware if you're using random forest for this, If you have the variance, for example on a noisy time series, then the variance is going to be so important, because random forest really like noise.
Read the Docs
Read the documentation.
It's going to tell you what is in a model, and especially regularisation, or little quirks that the maintainers implement to make it more useful for the general public and not just, well, your specific discipline.
It's going to be in the documentation, and it's going to be so important to know.
Ensemble models
Ensembles can combine different kinds of models with different strengths, and different, well, drawbacks.
Like the Voting Classifier.
Always think if a model should even be built
Always consider first if a model should even be built.
If it has facial recognition, it's almost always a no.
Remove correlated samples from training data
Before you even start, remove all the correlated samples from your training data.
Dare move away from defaults
The default values in your machine learning libraries are rarely great for real-world applications.
Especially the learning rate you'll have to play around with.
Log your experiments
Use an experiment-logging platform like ML Flow or Weights & Biases.
It's basically like using Git, because you can go back in history and look at what experiments you already ran, and often even save snapshot right from your models.
Build smaller models
A lot of the problems I worked on were solved by reducing the complexity of the model, and being able to build it up slowly instead of randomly trying to make it bigger.
Change Kaggle Sorting
When you look at Kaggle, and you want to find great data sets or code, then especially when you're looking at older, what's it called, older competitions, change the sorting order, the standard sorting is hotness, and that is terrible for old ones.
You want to change it to most votes, because then you can actually see the really popular notebooks and often winning solutions.
Learn from Kaggle
On that note, Kaggle is a fantastic platform to find data sets and code for problems you are working on.
Make ablation studies
Ablation studies are a fantastic way to find out which parts of your iterative model are actually making the model better.
Check out regularization techniques
Familiarise yourself with regularisation techniques Lasso and Ridge are great, which is L1 and L2 norm.
But you also want to check for dropout, noise injection, and data augmentation as well.
Learning Rate Scheduler
Always use a learning rate scheduler, something like ReduceLROnPlateau in Keras, where automatically when your validation is plateauing, the learning rate is decreased.
That way you find like a basin in your loss, well, loss landscape.
And then you focus in by going smaller in your learning rate.
On Pytorch and Tensorflow.
Don't overfit by hand
Be aware that you can actually overfit your model by hand.
If you test against your test set multiple times, you are actually overfitting by hand.
So only test on the test set once, and otherwise reshuffle your entire data and start anew.
Create decorrelated validation and test sets
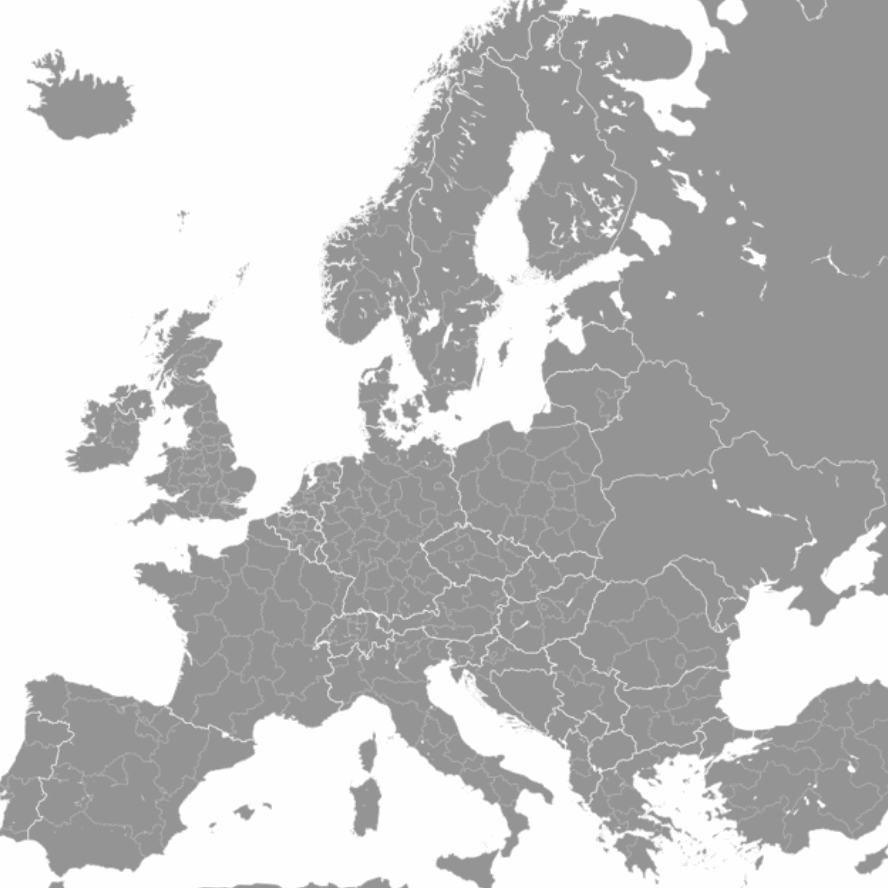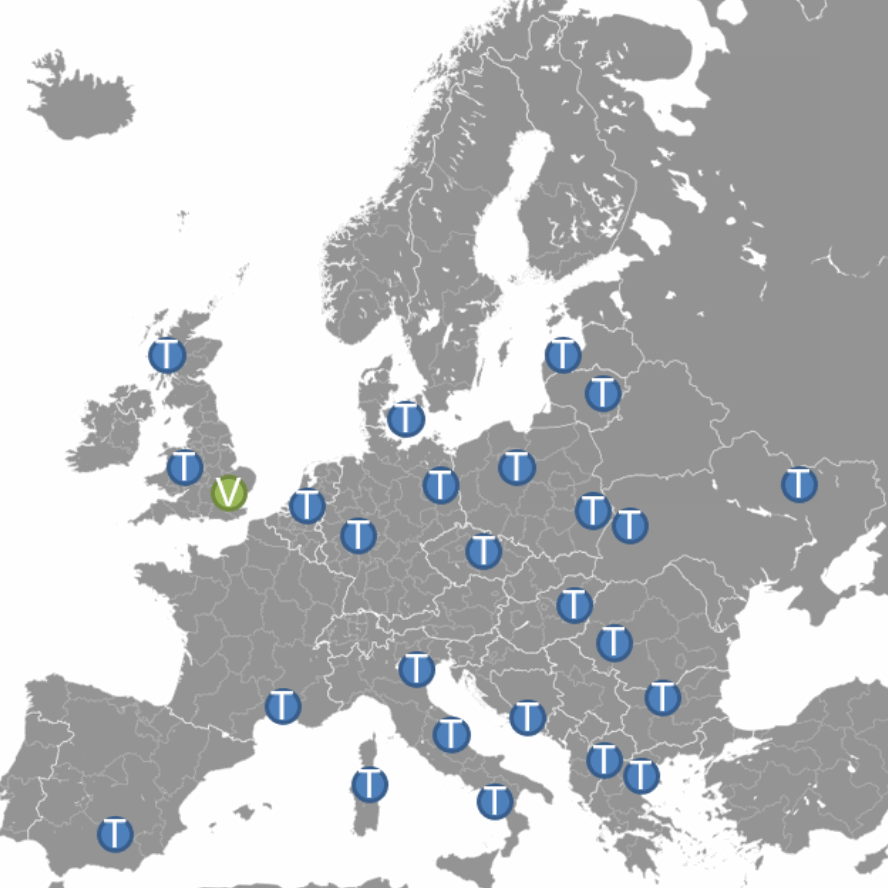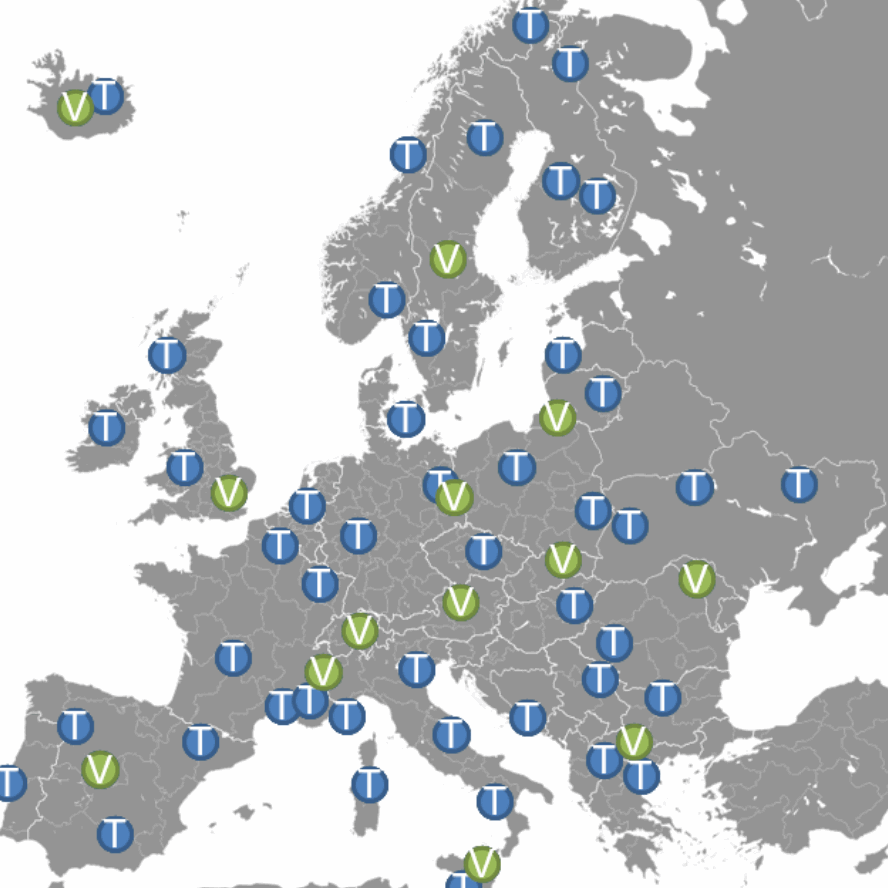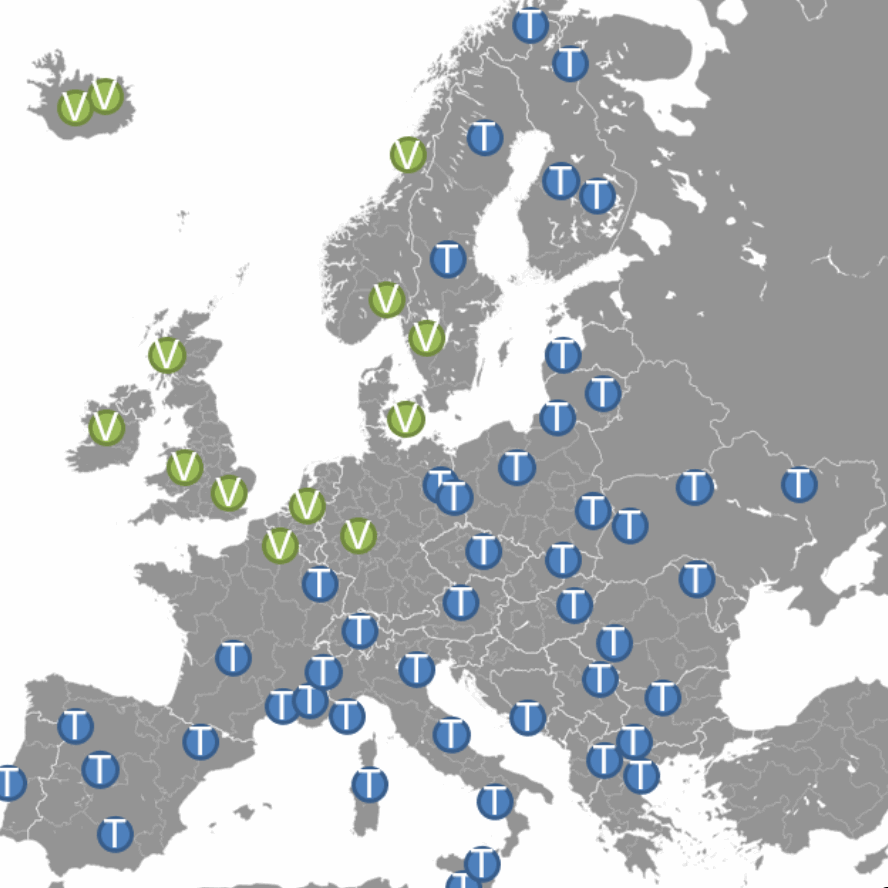
Your data is probably correlated in some way.
Time series are correlated in time because things that are closer to each other in time are more important to each other, inform each other more.
And spatial data is well, things that are actually closer, not just closer in time to each other, are more important.
And if you want to have a proper test and validation, you have to decorrelate your test and correlation set as much as you can.
Create Tensors on device
And I actually have a small ebook that I give away with my newsletter, which is going to be in the description, where I talk about more of this.
If you want to speed up your training, then create tensors directly on the device with the device keyword, instead of using the method dot CUDA.
size = (12, 23, 34) torch.rand(size).cuda()
versus
size = (12, 23, 34) torch.rand(size, device=torch.device("cuda"))
Fix all randomness for publication
For publication of your code and everything reporting you'll want to read the documentation about reproducibility, because there's always going to be that one source of randomness that you forget to make deterministic.
Visualize your training
Always use plots of your training and your convergence, because that way you can actually, well, you can see how it's doing and where there are plateaus and everything.
Tools like MLflow and Weights & Biases will create those automatically.
Compare models with AIC
Always use statistics to compare your models, like the AIC or Akaike information criterion are great to see which models are actually outperforming the others.
Publish your model weights
Publish your model weights.
That way you enable comparisons.
People can actually build on your solution and possibly even benchmark against it.
Look at your outputs
Better numbers are great, but consider that you always have to look at your actual output data.
Models sometimes find loopholes and they just, well, the outputs are just garbage, and you want to see that.
Don't just trust the numbers, always inspect the actual outputs.
Huber loss
In physical systems, try the Huber loss.
The Huber loss actually is linear on the sides, and it is still convex in the middle.
It comes from information theory, and it works really great on systems that work over large scales. So, physical data.
Trust domain scientists
Every field that you work in is going to have some assumptions that don't hold under scrutiny.
They are usually born out of- They are usually born out of smaller data and smaller compute.
However, as a foreigner to the field, like data scientist that isn't a domain scientist, you are very unlikely to actually find those.
So it is safe to assume that assumptions that domain experts make about their data and their field hold true.
Don't believe all old ML wisdom
Don't believe machine learning wisdom.
Don't believe all machine learning wisdom.
A lot of ancient wisdom has been gained through decades, and, well, is often on bad validation. Smaller neural networks that don't have the types of regularisation that we have this day.
And yeah, also we are much better with our optimizers with all the standards that we have now.
We actually know now that machine learning is actually really good on noise or noisy data. We use ML to correct models where we already know the signal for the noise.
So don't take every old wisdom for granted.
A lot of them, you definitely have to take with a grain of salt.